OpenCL Programming
Material by: James Perry, Kevin Stratford
Outline
- Background
- OpenCL terminology
- Work groups and work items
- Programming with OpenCL
- Initialising OpenCL and device discovery
- Allocating and copying memory
- Declaring a kernel
- Specifying kernel arguments and launching kernels
- Some comments
Background
What is OpenCL?
- An open standard for parallel programming using heterogeneous architectures
- Originally developed by Apple
- Maintained by the Khronos Group http://www.khronos.org/
- Supported by many manufacturers, e.g., AMD, ARM, Intel, NVIDIA, ...
- Same code will, in principle, run on all types of hardware
OpenCL Components
- Consists of:
- A programming language based on ANSI C for writing kernels
- Running kernels on devices
- An API for associated management of device, memory, kernels, and so on.
- Kernel functions often compiled at runtime
- Same code will run on many different devices (it is portable)
Work Items and Work Groups
- In OpenCL, each problem is composed of an array of work items
- May be one-dimensional, two-dimensional or three-dimensional
- The domain is sub-divided into work groups
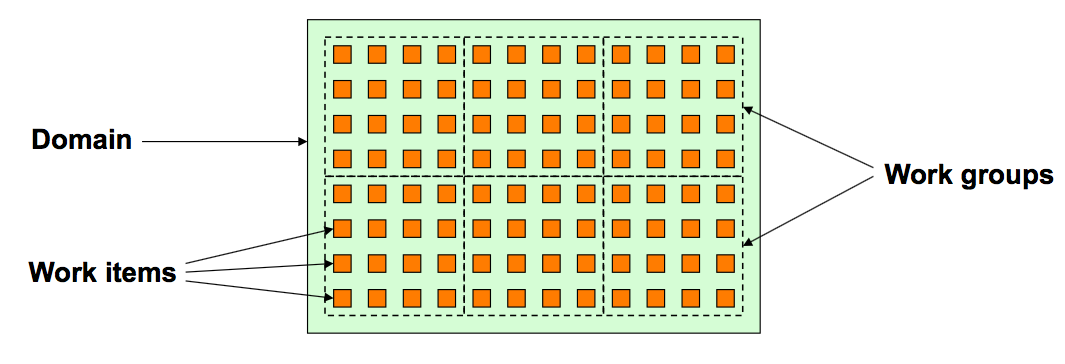
- Here: global dimension $12 \times 8$; local dimension $4 \times 4$
Host kernel
/* Consider this host code, which computes c = a + b
* for a 1-d vector of floats of length n: */
void add_vectors(float * a, float * b, float * c, int n) {
int i;
for (i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}
}
OpenCL kernel
/* Here is an equivalent OpenCL kernel */
__kernel void add_vectors(__global float * a,
__global float * b,
__global float * c) {
int i;
/* There is no loop: each work item processes a separate
* array element */
i = get_global_id(0);
c[i] = a[i] + b[i];
}
/* This OpenCL function determines the global index */
size_t get_global_id(uint dimidx);
Work Groups
- All the work items in the same work group are scheduled on the same processing unit. E.g., on the same SM on an NVIDIA card.
- Synchronisation is possible between work items in the same work group
- Synchronisation not possible between work groups
- Items in the same work group share same local memory
OpenCL host-side programming
Initialising OpenCL
#include "CL/opencl.h"
- Can be rather a long-winded process
- Performed via OpenCL API functions:
- Find the platform you require (e.g., CPU or GPU)
- Find the target device on that platform
- Create a context and command queue on the target device
- Compile your kernel (at run time) for the device
- Queue the kernel for execution
Allocating device memory
/* Device global memory is referenced on host by opaque
* "cl_mem" handles declared, e.g.: */
cl_mem deviceMemory;
/* Allocations are made in relevant OpenCL context: */
deviceMemory = clCreateBuffer(clContext, CL_MEM_READ_WRITE, size,
NULL, ierr);
/* ... perform work ... */
/* Device memory released via: */
ierr = clReleaseMemObject(deviceMemory);
Copying to and from device memory
/* Transfer between host and device typically involves: */
ierr = clEnqueueWriteBuffer(clQueue, buffer, CL_TRUE, 0, size,
host_ptr, 0, NULL, NULL);
/* ... perform required computation ... */
ierr = clEnqueueReadBuffer(clQueue, buffer, CL_TRUE, 0, size,
host_ptr, 0, NULL, NULL);
/* Note CL_TRUE indicates that these are blocking transfers;
* data may be used when the call returns.
* The final three arguments may refer to other events in the
* command queue (arguemnts which are not active here). */
Executing a kernel
cl_int ierr;
/* If we have a kernel:
* __kernel void add_vectors(float * d_input, int n); */
/* Declare kernel arguments: */
ierr = clSetKernelArg(clKernel, 0, sizeof(cl_mem), &d_input);
ierr = clSetKernelArg(clKernel, 1, sizeof(int), &size);
ierr = clEnqueueNDRangeKernel(clQueue, clKernel, ndim, NULL,
globalSize, localSize,
0, NULL, NULL);
/* Wait for all work groups to finish */
ierr = clFinish(clQueue);
Writing kernels
- OpenCL kernels are functions that run on the device
- Written in separate source file (cf. host code)
- Often .cl extension
- Often compiled at runtime
- OpenCL C kernel language is a subset of ANSI C
- Work item functions, work group functions ...
Memory space qualifiers
-
__global - Global memory
- Allocatable with read/write access on host
- Available to all work groups on a device (may be slow)
-
__constant - Constant memory
- Read-only fast cache memory on device (may be of limited capacity)
- Available (read-only) to all work groups/items
-
__local - Local memory
- Shared memory local to an individual work group
- Use schynchronisation to control updates
Some Comments
- Very general and therefore very flexible and portable
- Can be verbose so use libraries to help
- Kernel side somewhat more limited than CUDA (eg. no standard headers in kernel code)
- There do exist Fortran interfaces
- Quite a lot of activity in C++/SPIR/SYCL standards area